Key Concepts¶
Overview¶
Databay is a Python interface for scheduled data transfer.
It facilitates transfer of (any) data from A to B, on a scheduled interval.
In Databay, data transfer is expressed with three components:
Inlets- for data production.Outlets- for data consumption.Links- for handling the data transit between inlets and outlets.
Scheduling is implemented using third party libraries, exposed through the BasePlanner interface. Currently two BasePlanner implementations are available - using Advanced Python Scheduler (ApsPlanner) and Schedule (SchedulePlanner).
# Create an inlet, outlet and a link.
http_inlet = HttpInlet('https://some.test.url.com/')
mongo_outlet = MongoOutlet('databay', 'test_collection')
link = Link(http_inlet, mongo_outlet, datetime.timedelta(seconds=5))
# Create a planner, add the link and start scheduling.
planner = ApsPlanner(link)
planner.start()
Every 5 seconds this snippet will pull data from a test URL, and write it to MongoDB.
While Databay comes with a handful of built-in inlets and outlets, its strength lies in extendability. To use Databay in your project, create concrete implementations of Inlet and Outlet classes that handle the data production and consumption functionality you require. Databay will then make sure data can repeatedly flow between the inlets and outlets you create. Extending Inlets and extending Outlets is easy and has a wide range of customization. Head over to Extending Databay section for a detailed explanation.
Inlets, Outlets and Links¶
Databay treats data transfer as a unidirectional graph, where data flows from Inlet nodes to Outlet nodes. An example of an inlet and outlet could be an HTTP request client and a CSV writer respectively.

The relationship between the inlets and outlets is explicitly defined as a Link.

One link may connect multiple inlets and outlets.
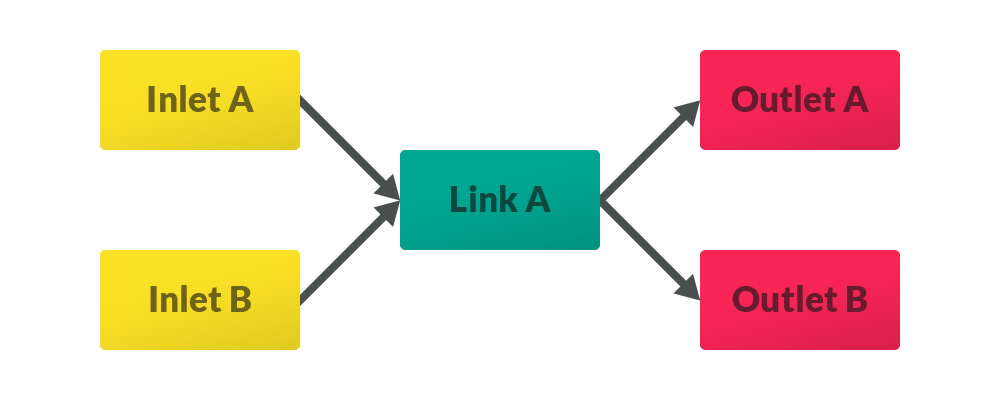
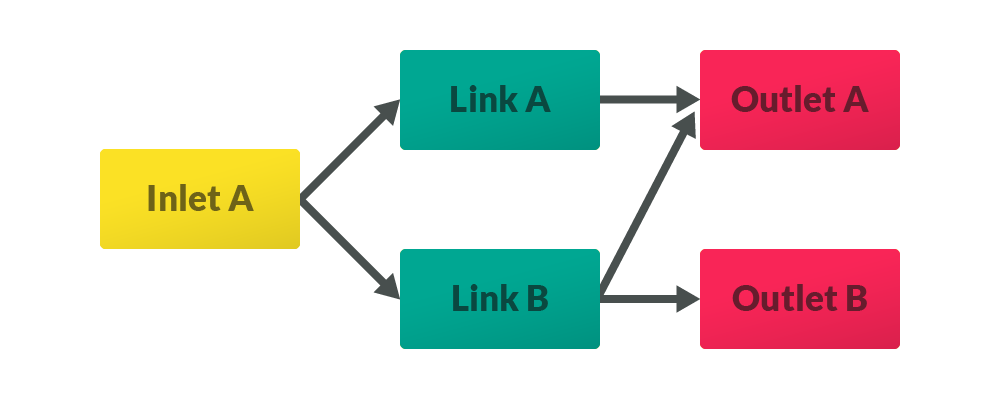
One inlet or outlet can be connected through multiple links.
Link transfer¶
One cycle of data production, propagation and consumption is called transfer. During transfer, a link will pull data from all its inlets and then push that collected data to all its outlets.
Each link contains an interval at which it will run the data transfer. This interval is specified on construction with the interval parameter of type datetime.timedelta.
Link([inlets], [outlets], interval=datetime.timedelta(minutes=10))
One quantity of data handled by Databay is represented with a Record.
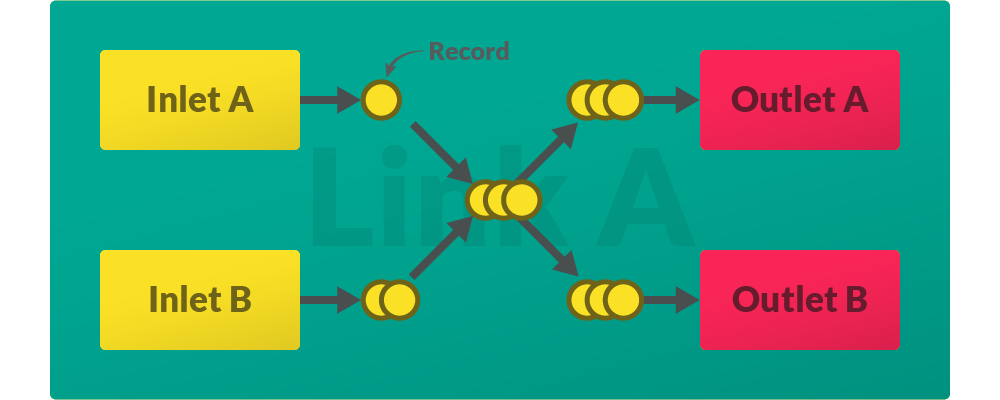
Both pulling and pushing is executed asynchronously, yet pushing only starts once all inlets have finished returning their data.
There’s a lot more you can do to your data during a transfer - such as filtering, buffering, grouping and transforming. Head over to Advanced Concepts to learn more.
Transfer Update
Each transfer is identified by a unique Update object that is available to all inlets and outlets affected by that transfer. It contains the tags of the governing link (if specified) and an incremental integer index. Use the str(update) to get a formatted string of that update.
# for link called 'twitter_link' and the 16th transfer execution.
>>> print(update)
twitter_link.16
Records¶
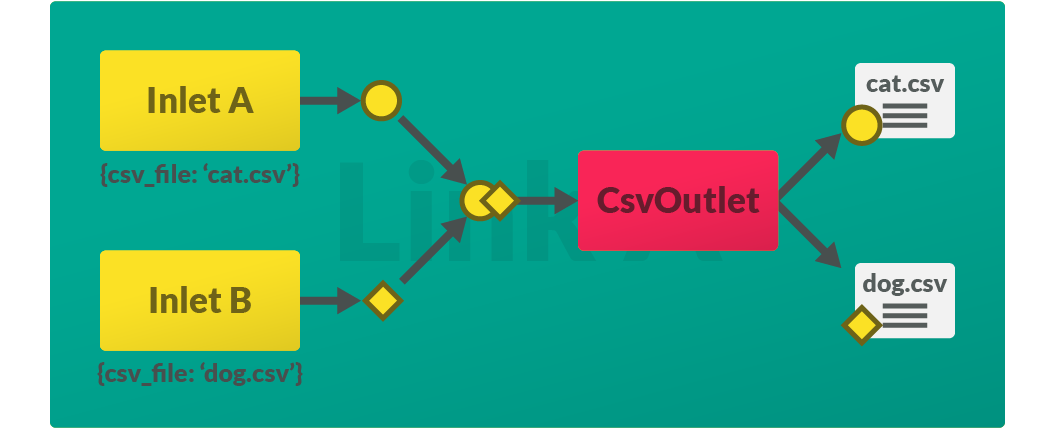
Records are data objects that provide a unified interface for data handling across Databay. In addition to storing data produced by inlets, records may also carry individual metadata. This way information can be passed between inlets and outlets, facilitating a broad spectrum of custom implementations. For instance one CsvOutlet could be used for writing into two different csv files depending on which inlet the data came from.
Scheduling¶
The principal functionality of Databay is to execute data transfer repeatedly on a pre-defined interval. To facilitate this, links are governed by a scheduler object implementing the BasePlanner class. Using the concrete scheduling functionality, links’ transfers are executed in respect with their individual interval setting.
To schedule a link, all you need to do is to add it to a planner and call start to begin scheduling.
link = Link(some_inlet, some_outlet, timedelta(minutes=1))
planner = SchedulePlanner(link)
planner.start()
Databay provides two built-in BasePlanner implementations based on two popular Python scheduling libraries:
ApsPlanner- using Advanced Python Scheduler.SchedulePlanner- using Schedule.
While they differ in the method of scheduling, threading and exception handling, they both cover a reasonable variety of scheduling scenarios. Please refer to their appropriate documentation for more details on the difference between the two.
You can easily use a different scheduling library of your choice by extending the BasePlanner class and implementing the link scheduling and unscheduling yourself. See Extending BasePlanner for more.
Start and shutdown¶
Start
To begin scheduling links you need to call start on the planner you’re using. Both ApsPlanner and SchedulePlanner handle start as a synchronous blocking function. To run start without blocking the current thread, wrap its call within a new thread or a process:
th = Thread(target=planner.start)
th.start()
Shutdown
To stop scheduling links you need to call shutdown(wait:bool=True) on the planner you’re using. Note that this may or may not let the currently transferring links finish, depending on the implementation of the BasePlanner that you’re using. Both ApsPlanner and SchedulePlanner allow waiting for the links if shutdown is called passing True as the wait parameter.
on_start and on_shutdown
Just before scheduling starts, Inlet.on_start and Outlet.on_start callbacks will be propagated through all inlets and outlets. Consequently, just after scheduling shuts down, Inlet.on_shutdown and Outlet.on_shutdown callbacks will be propagated through all inlets and outlets. In both cases, these callbacks will be called only once for each inlet and outlet. Override these callback methods to implement custom starting and shutdown behaviour in your inlets and outlets.
immediate_transfer
By default BasePlanner will execute Link.transfer function on all its links once upon calling BasePlanner.start. This is to avoid having to wait for the link’s interval to expire before the first transfer. You can disable this behaviour by passing immediate_transfer=False parameter on construction.
Exception handling¶
If exceptions are thrown during transfer, both planners can be set to log and ignore these by passing the ignore_exceptions=True parameter on construction. This ensures transfer of remaining links can carry on even if some links are erroneous. If exceptions aren’t ignored, both ApsPlanner and SchedulePlanner will log the exception and gracefully shutdown.
Additionally, each Link can be configured to catch exceptions by passing ignore_exceptions=True on construction. This way any exceptions raised by individual inlets and outlets can be logged and ignored, allowing the remaining nodes to continue execution and for the transfer to complete.
# for planners
planner = SchedulePlanner(ignore_exceptions=True)
planner = ApsPlanner(ignore_exceptions=True)
# for links
link = Link(..., ignore_exceptions=True)
Logging¶
All classes in Databay are configured to utilise a Python Logger called databay or its child loggers. Databay utilises a custom StreamHandler with the following signature:
%Y-%m-%d %H:%M:%S.milis|levelname| message (logger name)
For example:
2020-07-30 19:51:41.318|D| http_to_mongo.0 transfer (databay.Link)
By default Databay will only log messages with WARNING priority or higher. You can manually enable more verbose logging by calling:
logging.getLogger('databay').setLevel(logging.DEBUG)
# Or do it only for a particular child logger:
logging.getLogger('databay.ApsPlanner').setLevel(logging.DEBUG)
You can attach new handlers to any of these loggers in order to implement custom logging behaviour - such as a FileHandler to log into a file, or a separate StreamHandler to customise the print signature.
Motivation¶
The data flow in Databay is different from a more widely adopted Observer Pattern, where data production and propagation are represented by one object, and consumption by another. In Databay data production and propagation is split between the Inlet and Link objects. This results in a data flow model in which each stage - data transfer, production and consumption - is independent from the others. Inlets are only concerned with producing data, Outlets only with consuming data and Links only with transferring data. Such a model is motivated by separation of concerns and by facilitating custom implementation of data producers and consumers.
Next Steps