Processors¶
Processors are a middleware pipeline that alters the records transferred from inlets to outlets. Two most common usages of these would be:
Filtering - removing some or all records before feeding them to outlets.
Transforming - altering the records before feeding them to outlets.
Simple example¶
# Example filtering
def only_large_numbers(records: List[Records]):
result = []
for record in records:
if record.payload >= 100:
result.push(record)
return result
# Example transforming:
def round_to_integers(records: List[Records]):
for record in records:
record.payload = round(record.payload)
return records
# pass to a link
link = Link(..., processors=[only_large_numbers, round_to_integers])
The processor pipeline used in the above example will turn the following list:
[99.999, 200, 333.333]
into:
[200, 333]
Note that 99.999 got filtered out given the order of processors. If we were to swap the processors, the rounding would occur before filtering, allowing all three results through the filter.
Processors explained¶
A processor is a callable function that accepts a list of records and returns a (potentially altered) list of records.
Processors are called in the order in which they are passed, after all inlets finish producing their data. The result of each processor is given to the next one, until finally the resulting records continue the transfer normally.
Link vs Outlet processors¶
Databay supports two types of processors, depending on the scope at which they operate.
Link processor- applied to all records transferred by that link.Outlet processor- applied only to records consumed by the particular outlet.
This distinction can be used to determine at which level a particular processor is to be applied.
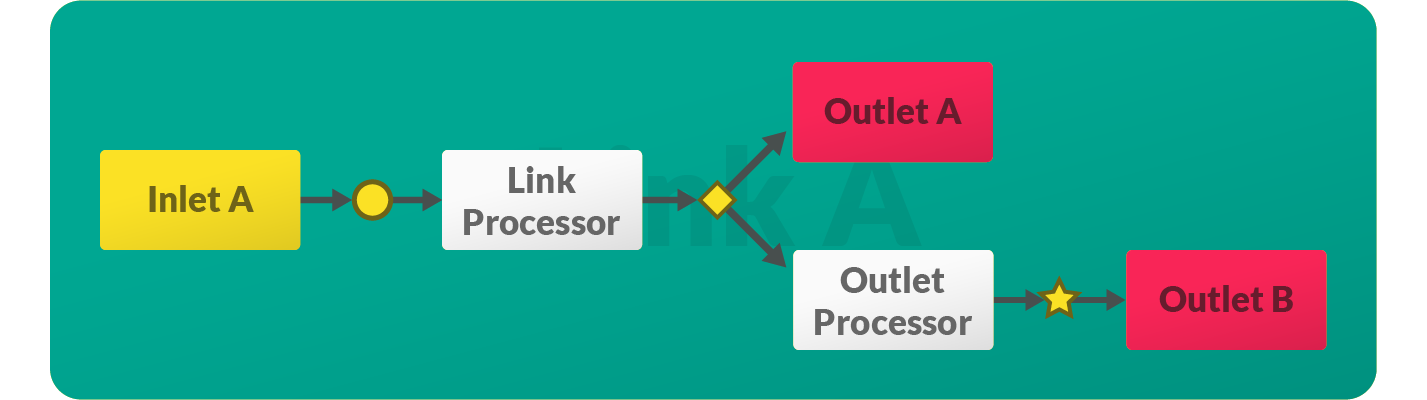
Observe in the diagram above that the Outlet A will receive records modified only by the Link Processor. At the same time, the Outlet B will receive records modified first by the Link Processor, then by the Outlet Processor.
For example:
Link processor- A filtering processor that removes duplicate records produced by an inlet could be applied to all records at link level.
def remove_duplicates(records: List[Record]):
result = []
for record in records:
if record not in result:
result.append(record)
return result
link = Link(..., processors=remove_duplicates)
Outlet processor- A filtering processor that filters out records already existing in a CSV file could be applied only to the CsvOutlet, preventing duplicate records from being written to a CSV file, yet otherwise allowing all records to be consumed by the other outlets in the link.
def filter_existing(records: List[Record]):
with open(os.fspath('./data/records.csv'), 'r') as f:
reader = csv.DictReader(csv_file)
existing = []
for row in reader:
for key, value in row.items():
existing.append(value)
result = []
for record in records:
if record.payload not in existing:
result.append(record)
return result
csv_outlet = CsvOutlet(..., processors=filter_existing)
link = Link(inlets, csv_outlet, ...)
Link processors are used before Groupers, while Outlet processors are used after.
Best practices¶
Responsibility
Databay doesn’t make any further assumptions about processors - you can implement any type of processors that may suit your needs. This also means Databay will not ensure the records aren’t corrupted by the processors, therefore you need to be conscious of what each processor does to the data.
If you wish to verify the integrity of your records after processing, attach an additional processor at the end of your processor pipeline that will validate the correctness of your processed records before sending it off to the outlets.